Apache Flink is a powerful, open-source stream processing framework that excels in real-time data processing and analytics. It provides capabilities to process both batch and streaming data with high throughput and low latency. Flink’s distributed architecture ensures that it can handle large volumes of data efficiently while maintaining fault tolerance and scalability.
What is Apache Flink?
Apache Flink is designed to handle the complexities of real-time data processing, offering features like stateful computation, event time processing, and exactly-once semantics. It supports both stream and batch processing, although the Dataset API, which was initially used for batch processing, has been deprecated in favor of the more unified DataStream API.
Why Use Apache Flink?
Flink is favored for its high performance and flexibility in managing data streams. Its features include:
Low Latency: Flink can process events in real-time with minimal delay.
Fault Tolerance: Ensures data consistency and recovery in case of failures.
Scalability: Handles scaling seamlessly by distributing processing across nodes.
State Management: Supports large-scale stateful computations.
Flink Concepts and APIs
To effectively use Flink, it’s essential to understand its core concepts and APIs. Here, we’ll cover the basic concepts and then dive into the APIs available for building Flink applications.
Bounded vs. Unbounded Data
In Flink, data can be classified into two types: bounded and unbounded.
Bounded Data: Refers to datasets with a defined beginning and end, such as batch data. The Dataset API, though deprecated, was initially designed for this type of processing.
Unbounded Data: Represents continuous streams of data with no predefined end, such as real-time logs or sensor data. The DataStream API is designed to handle unbounded data and is more suitable for streaming applications.
Scaling Applications
Apache Flink efficiently manages stateful streaming applications at scale by dividing them into parallel tasks across a cluster. This approach leverages extensive computing resources like CPUs, memory, disk space, and network bandwidth. Flink’s asynchronous and incremental checkpointing minimizes performance impact while ensuring exactly-once state consistency. In practice, Flink supports applications processing billions of events daily, managing terabytes of state, and utilizing thousands of CPU cores.
Leverage In-Memory Performance
Flink optimizes stateful applications for fast local state access. Task states are kept in memory whenever possible, or in efficient on-disk structures if the state is too large. This design minimizes processing delays by allowing tasks to quickly access local data. To ensure reliability, Flink periodically and asynchronously checkpoints this state to durable storage, maintaining exactly-once consistency even in the event of failures.
Flink APIs
Flink provides several APIs for different use cases:
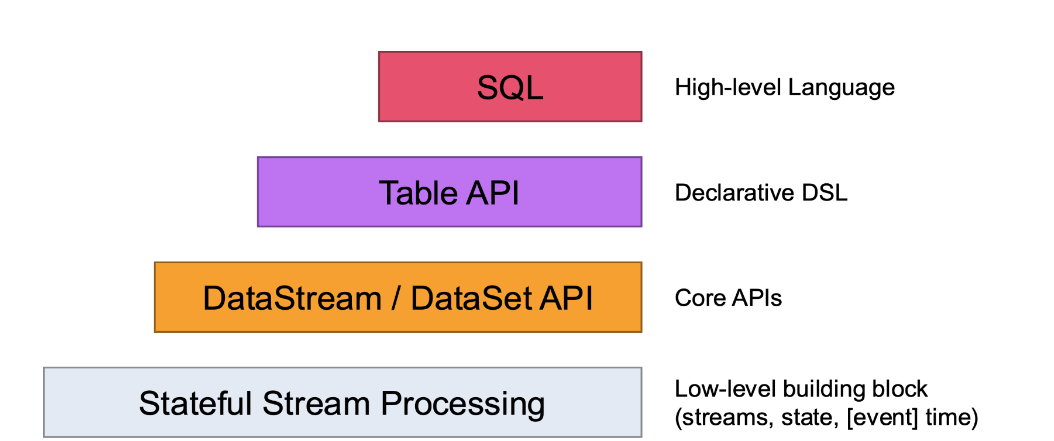
Flink’s lowest level of abstraction is focused on stateful and timely stream processing. This is achieved through the ProcessFunction, which is part of the DataStream API. With this function, users can manage events from one or more streams in a flexible and reliable manner. It ensures consistent, fault-tolerant state management, which is crucial for robust data processing.
Additionally, the ProcessFunction provides the capability to register event time and processing time callbacks. These callbacks allow programs to perform complex computations by reacting to specific timing conditions, enabling sophisticated processing logic tailored to the needs of the application
DataStream API
The DataStream API is ideal for most applications, offering higher-level abstractions for both bounded and unbounded streams. It provides essential building blocks for data processing, such as transformations, joins, aggregations, windows, and state management. Data types are represented as classes in the respective programming languages, ensuring easy integration.
While the low-level ProcessFunction can be used for detailed control, it integrates seamlessly with the DataStream API, allowing developers to use it only when necessary. This flexibility makes the DataStream API a powerful choice for developing real-time data processing applications.
Deprecated DataSet API
The Dataset API, designed for bounded data sets, offered additional primitives like loops and iterations. However, it is now deprecated. Developers are encouraged to transition to the DataStream API, which provides more advanced features and better support for both bounded and unbounded data. The shift to the DataStream API ensures applications are built using the latest stream processing technology, making them more scalable and maintainable.
Table API
The Table API is a declarative DSL (Domain Specific Language) focused on working with tables, which can represent dynamically changing data streams. It follows an extended relational model, attaching schemas to tables like those in relational databases. This API allows operations such as select, project, join, group-by, and aggregate, making it familiar to those with SQL experience.
Unlike procedural code, Table API programs define what logical operations should be performed rather than how to execute them. This makes the Table API less expressive but more concise compared to Core APIs, reducing the amount of code needed. Despite this, it remains extensible through various user-defined functions.
Additionally, Table API programs benefit from an optimizer that applies optimization rules before execution, ensuring efficient performance. This balance of ease of use and performance optimization makes the Table API a powerful tool for data processing in Flink. It also supports seamless conversion between tables and DataStream/DataSet, enabling a hybrid approach where you can integrate Table API operations with DataStream and DataSet APIs for a more comprehensive data processing solution.
SQL API
Built on top of the Table API, The SQL API offers a way to interact with data using SQL queries. It is the highest level of abstraction offered by Flink.